
信息抽取是一个宽泛的概念,指的是从非结构化文本中提取结构化信息的一类技术。这类技术依然分为基于规则的正则匹配、有监督学习和无监督学习等各种实现方法。一些简单实用的无监督学习方法,由于不需要标注语料库,所以可以利用海量的非结构化文本。
按照颗粒度从小到大的顺序,总结抽取新词、关键词、关键短语和关键句的无监督学习方法。
一、新词提取
1.概述
新词是一个相对的概念,每个人的标准都不一样,所以我们这里定义: 词典之外的词语(OOV)称作新词。 新词的提取对中文分词而言具有重要的意义,因为语料库的标注成本很高。那么如何修订领域词典呢,此时,无监督的新词提取算法就体现了现实意义。
2.基本原理
- 提取出大量文本(生语料)中的词语,无论新旧。
- 用词典过滤掉已有的词语,于是得到新词。 步骤 2 很容易,关键是步骤 1,如何无监督的提取出文本中的单词。给定一段文本,随机取一个片段,如果这个片段左右的搭配很丰富,并且片段内部成分搭配很固定,则可以认为这是一个词。将这样的片段筛选出来,按照频次由高到低排序,排在前面的有很高概率是词。 如果文本足够大,再用通用的词典过滤掉“旧词”,就可以得到“新词”。 片段外部左右搭配的丰富程度,可以用信息熵来衡量,而片段内部搭配的固定程度可以用子序列的互信息来衡量。
3.信息熵 在信息论中,信息熵( entropy )指的是某条消息所含的信息量。它反映的是听说某个消息之后,关于该事件的不确定性的减少量。比如抛硬币之前,我们不知道“硬币正反”这个事件的结果。但是一旦有人告诉我们“硬币是正面”这条消息,我们对该次抛硬币事件的不确定性立即降为零,这种不确定性的减小量就是信息熵。公式如下:
$$H(X)=-\sum_{x} p(x) \log p(x)$$ 给定字符串 S 作为词语备选,X 定义为该字符串左边可能出现的字符(左邻字),则称 H(X) 为 S 的左信息熵,类似的,定义右信息熵 H(Y),例如下列句子:
两只蝴蝶飞啊飞
这些蝴蝶飞走了
那么对于字符串蝴蝶,它的左信息熵为1,而右信息熵为0。因为生语料库中蝴蝶的右邻字一定是飞。假如我们再收集一些句子,比如“蝴蝶效应”“蝴蝶蜕变”之类,就会观察到右信息熵会增大不少。
左右信息熵越大,说明字符串可能的搭配就越丰富,该字符串就是一个词的可能性就越大。
光考虑左右信息熵是不够的,比如“吃了一顿”“看了一遍”“睡了一晚”“去了一趟”中的了一的左右搭配也很丰富。为了更好的效果,我们还必须考虑词语内部片段的凝聚程度,这种凝聚程度由互信息衡量。
4.互信息
互信息指的是两个离散型随机变量 X 与 Y 相关程度的度量,定义如下:
$$
\begin{aligned}
I(X ; Y) & =\sum_{x, y} p(x, y) \log \frac{p(x, y)}{p(x) p(y)} \\
& =E_{p(x, y)} \log \frac{p(x, y)}{p(x) p(y)}
\end{aligned}
$$
互信息的定义可以用韦恩图直观表达:
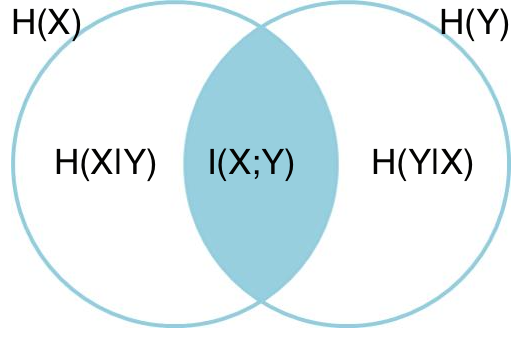
其中,左圆圈表示H(X),右圆圈表示H(Y)。它们的并集是联合分布的信息熵H(X,Y),差集有多件嫡,交集就是互信息。可见互信息越大,两个随机变量的关联就越密切,或者说同时发生的可能性越大。
片段可能有多种组合方式,计算上可以选取所有组合方式中互信息最小的那一种为代表。有了左右信息熵和互信息之后,将两个指标低于一定阈值的片段过滤掉,剩下的片段按频次降序排序,截取最高频次的 N 个片段即完成了词语提取流程。
5.实现。
用四大名著来提起100个高频词。 代码请见(语料库自动下载): extract_word.py
from pyhanlp import *
import zipfile
import os
from pyhanlp.static import download, remove_file, HANLP_DATA_PATH
def test_data_path():
"""
获取测试数据路径,位于$root/data/test,根目录由配置文件指定。
:return:
"""
data_path = os.path.join(HANLP_DATA_PATH, 'test')
if not os.path.isdir(data_path):
os.mkdir(data_path)
return data_path
## 验证是否存在 MSR语料库,如果没有自动下载
def ensure_data(data_name, data_url):
root_path = test_data_path()
dest_path = os.path.join(root_path, data_name)
if os.path.exists(dest_path):
return dest_path
if data_url.endswith('.zip'):
dest_path += '.zip'
download(data_url, dest_path)
if data_url.endswith('.zip'):
with zipfile.ZipFile(dest_path, "r") as archive:
archive.extractall(root_path)
remove_file(dest_path)
dest_path = dest_path[:-len('.zip')]
return dest_path
HLM_PATH = ensure_data("红楼梦.txt", "http://file.hankcs.com/corpus/红楼梦.zip")
XYJ_PATH = ensure_data("西游记.txt", "http://file.hankcs.com/corpus/西游记.zip")
SHZ_PATH = ensure_data("水浒传.txt", "http://file.hankcs.com/corpus/水浒传.zip")
SAN_PATH = ensure_data("三国演义.txt", "http://file.hankcs.com/corpus/三国演义.zip")
WEIBO_PATH = ensure_data("weibo-classification", "http://file.hankcs.com/corpus/weibo-classification.zip")
def test_weibo():
for folder in os.listdir(WEIBO_PATH):
print(folder)
big_text = ""
for file in os.listdir(os.path.join(WEIBO_PATH, folder)):
with open(os.path.join(WEIBO_PATH, folder, file)) as src:
big_text += "".join(src.readlines())
word_info_list = HanLP.extractWords(big_text, 100)
print(word_info_list)
def extract(corpus):
print("%s 热词" % corpus)
## 参数如下
# reader: 文本数据源
# size: 控制返回多少个词
# newWordsOnly: 为真时,程序将使用内部词库过滤掉“旧词”。
# max_word_len: 控制识别结果中最长的词语长度
# min_freq: 控制结果中词语的最低频率
# min_entropy: 控制结果中词语的最低信息熵的值,一般取 0.5 左右,值越大,越短的词语就越容易提取
# min_aggregation: 控制结果中词语的最低互信息值,一般取 50 到 200.值越大,越长的词语越容易提取
word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(corpus), 100)
print(word_info_list)
# print("%s 新词" % corpus)
# word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(corpus), 100, True)
# print(word_info_list)
if __name__ == '__main__':
extract(HLM_PATH)
extract(XYJ_PATH)
extract(SHZ_PATH)
extract(SAN_PATH)
#test_weibo()
# 更多参数
word_info_list = HanLP.extractWords(IOUtil.newBufferedReader(HLM_PATH), 100, True, 4, 0.0, .5, 100)
print(word_info_list)运行结果如下:

虽然我们没有在古典文学语料库上进行训练,但新词识别模块成功的识别出了麝月、高太尉等生僻词语,该模块也适用于微博等社交媒体的不规范文本。
二、 关键词提取
词语颗粒度的信息抽取还存在另一个需求,即提取文章中重要的单词,称为关键词提起。关键词也是一个没有定量的标准,无法统一语料库,所以就可以利用无监督学习来完成。
分别介绍词频、TF-IDF和TextRank算法,单文档提起可以用词频和TextRank,多文档可以使用TF-IDF来提取关键词。
1.词频统计
关键词通常在文章中反复出现,为了解释关键词,作者通常会反复提及它们。通过统计文章中每种词语的词频并排序,可以初步获取部分关键词。 不过文章中反复出现的词语却不一定是关键词,例如“的”。所以在统计词频之前需要去掉停用词。 词频统计的流程一般是分词、停用词过滤、按词频取前 n 个。其中,求 m 个元素中前 n (n<=m) 大元素的问题通常通过最大堆解决,复杂度为 O(mlogn)。HanLP代码如下:
from pyhanlp import *
TermFrequency = JClass('com.hankcs.hanlp.corpus.occurrence.TermFrequency')
TermFrequencyCounter = JClass('com.hankcs.hanlp.mining.word.TermFrequencyCounter')
if __name__ == '__main__':
counter = TermFrequencyCounter()
counter.add("加油加油中国队!") # 第一个文档
counter.add("中国观众高呼加油中国") # 第二个文档
for termFrequency in counter: # 遍历每个词与词频
print("%s=%d" % (termFrequency.getTerm(), termFrequency.getFrequency()))
print(counter.top(2)) # 取 top N
# 根据词频提取关键词
print('')
print(TermFrequencyCounter.getKeywordList("女排夺冠,观众欢呼女排女排女排!", 3))运行结果如下:
中国=2
中国队=1
加油=3
观众=1
高呼=1
[加油=3, 中国=2]
[女排, 观众, 欢呼]用词频来提取关键词有一个缺陷,那就是高频词并不等价于关键词。比如在一个体育网站中,所有文章都是奥运会报道,导致“奥运会”词频最高,用户希望通过关键词看到每篇文章的特色。此时,TF-IDF 就派上用场了。
2.TF-IDF
TF-IDF (Term Frequency-lnverse Document Frequency,词频-倒排文档频次)是信息检索中衡量一个词语重要程度的统计指标,被广泛用于Lucene、Solr、Elasticsearch 等搜索引擎。 相较于词频,TF-IDF 还综合考虑词语的稀有程度。在TF-IDF计算方法中,一个词语的重要程度不光正比于它在文档中的频次,还反比于有多少文档包含它。包含该词语的文档趣多,就说明它越宽泛, 越不能体现文档的特色。 正是因为需要考虑整个语料库或文档集合,所以TF-IDF在关键词提取时属于多文档方法。 计算公式如下:
$$
\begin{aligned}
\mathrm{TF}-\operatorname{IDF}(t, d) & =\frac{\mathrm{TF}(t, d)}{\mathrm{DF}(t)} \\
& =\operatorname{TF}(t, d) \cdot \operatorname{IDF}(t)
\end{aligned}
$$
其中,t 代表单词,d 代表文档,TF(t,d) 代表 t 在 d 中出现频次,DF(t) 代表有多少篇文档包含 t。DF 的导数称为IDF,这也是 TF-IDF 得名的由来。 当然,实际应用时做一些扩展,比如加一平滑、IDF取对数以防止浮点数下溢出。HanLP的示例如下:
from pyhanlp import *
TfIdfCounter = JClass('com.hankcs.hanlp.mining.word.TfIdfCounter')
if __name__ == '__main__':
counter = TfIdfCounter()
counter.add("《女排夺冠》", "女排北京奥运会夺冠") # 输入多篇文档
counter.add("《羽毛球男单》", "北京奥运会的羽毛球男单决赛")
counter.add("《女排》", "中国队女排夺北京奥运会金牌重返巅峰,观众欢呼女排女排女排!")
counter.compute() # 输入完毕
for id in counter.documents():
print(id + " : " + counter.getKeywordsOf(id, 3).toString()) # 根据每篇文档的TF-IDF提取关键词
# 根据语料库已有的IDF信息为语料库之外的新文档提取关键词
print('')
print(counter.getKeywords("奥运会反兴奋剂", 2))运行后如下:
《女排》 : [女排=5.150728289807123, 重返=1.6931471805599454, 巅峰=1.6931471805599454]
《女排夺冠》 : [夺冠=1.6931471805599454, 女排=1.2876820724517808, 奥运会=1.0]
《羽毛球男单》 : [决赛=1.6931471805599454, 羽毛球=1.6931471805599454, 男单=1.6931471805599454]
[反, 兴奋剂]观察输出结果,可以看出 TF-IDF 有效的避免了给予“奥运会”这个宽泛的词语过高的权重。
TF-IDF在大型语料库上的统计类似于一种学习过程,假如我们没有这么大型的语料库或者存储IDF的内存,同时又想改善词频统计的效果该怎么办呢?此时可以使用TextRank算法。
三、短语提取
在信息抽取领域,另一项重要的任务就是提取中文短语,也即固定多字词表达串的识别。短语提取经常用于搜索引擎的自动推荐,文档的简介生成等。
利用互信息和左右信息熵,我们可以轻松地将新词提取算法拓展到短语提取。只需将新词提取时的字符替换为单词, 字符串替换为单词列表即可。为了得到单词,我们依然需要进行中文分词。 大多数时候, 停用词对短语含义表达帮助不大,所以通常在分词后过滤掉。
代码如下:
# coding:utf-8
from pyhanlp import *
""" 短语提取"""
text = '''
办好人民满意教育的总体思路
当前,世界百年未有之大变局加速演进,中华民族伟大复兴进入不可逆转的历史进程。党的二十大报告明确了新时代新征程党和国家所处的历史方位,对以中国式现代化全面推进中华民族伟大复兴作出一系列重大部署。推动经济社会发展、提高综合国力和国际竞争力,归根结底要靠人才。教育是提高人民综合素质、促进人的全面发展的重要途径,是民族振兴、社会进步的重要基石,是对中华民族伟大复兴具有决定性意义的事业。强国必先强教,中国式现代化需要教育现代化的支撑。在新的起点上,教育工作要深入贯彻习近平总书记关于教育的重要论述,全面落实党的教育方针,坚持为党育人、为国育才,遵循教育规律和人才成长规律,顺应社会主要矛盾的变化,以高质量发展为主线,以深化教育改革为动力,以凝聚人心、完善人格、开发人力、培育人才、造福人民为目标,健全学校、家庭、社会育人机制,培养德智体美劳全面发展的社会主义建设者和接班人,加快建设教育强国、办好人民满意的教育。
(一)坚持立德树人的根本任务。习近平总书记强调,“我国是中国共产党领导的社会主义国家,这就决定了我们的教育必须把培养社会主义建设者和接班人作为根本任务,培养一代又一代拥护中国共产党领导和我国社会主义制度、立志为中国特色社会主义奋斗终身的有用人才。”培养什么人,是教育的首要问题。这是思考和谋划教育工作的逻辑起点,也是丝毫不能偏离的政治方向。青少年是价值观形成和塑造的关键时期,党的教育方针始终强调德育为先。要从学生身心特点和思想实际出发,持续深化思想政治理论课改革创新,用习近平新时代中国特色社会主义思想铸魂育人,推进思政课程和课程思政同向同行,把思想政治教育“小课堂”与社会“大课堂”贯通起来,提高思想政治教育的亲和力和针对性。人才培养是育人和育才相统一的过程,教育传授学生的不仅是知识,更重要的是价值观塑造、能力锻造、人格养成。教育无论发展到什么程度,第一位的是立德树人,引导学生树立正确的世界观、人生观、价值观,教会学生有能力、有责任、有爱心,全面发展、学有所长,培养出党和国家需要、对社会有用的人。
(二)坚持科学的教育理念。习近平总书记强调,“素质教育是教育的核心,教育要注重以人为本、因材施教,注重学用相长、知行合一”,“促进学生德智体美劳全面发展”。教育理念是教育实践的先导。教育是一门科学,兴教办学、人才成长有客观的规律。中华民族历来有崇文重教的优良传统,积累了丰富的教育经验和智慧,如有教无类、因材施教、循序渐进、温故知新、教学相长等。要坚定教育自信,弘扬我国优秀教育传统,吸收借鉴国际先进经验,构建德智体美劳全面培养的教育体系,深化体教融合,发挥劳动教育的育人功能,提升学生综合素质。适合的教育是最好的教育。每个学生的禀赋、潜质、特长不同,学校要坚持以学生为本,注重因材施教,探索多样化办学,对在某些方面确有专长的学生,通过个性化指导、兴趣小组等灵活教学管理方式进行重点培养;对学习困难的学生,用心发现他们的长处、耐心施教,使教育的选择更多样、成长的道路更宽广,努力让每个学生都有人生出彩的机会。树立科学的教育理念是一个长期的过程,需要学校、家庭、社会持续不懈的努力,守正笃实、久久为功,促进学生身心健康成长。
(三)坚持教育事业的公益属性。习近平总书记强调,要“坚持教育公益性原则,把教育公平作为国家基本教育政策”。教育事关国民素质提升和国家未来发展,是重要的公共服务。我国教育法规定,“教育活动必须符合国家和社会公共利益”。在保证公益性的前提下,政府以外的民办教育机构提供教育服务,对于扩大学位供给、满足多样教育需求来说是有益的。但良心的行业不能变成逐利的产业,更不能让资本在教育领域无序扩张,加重群众负担,破坏教育生态。近年来推进“双减”工作、规范民办义务教育,同时大力发展普惠园、推进义务教育城乡均衡、保障随迁子女入学、开展控辍保学,都是坚持教育的公益性。教育公平是社会公平的重要基础,既在于均等化的基本公共服务,更体现在教育机会、资源配置、制度政策的公平。促进教育公平不是削峰填谷,关键在补齐短板、提高质量,办好每一所学校、教好每一个学生。数字化线上教育是学校教育和课堂教学的补充和延伸,我国城乡学生共享全国名师、名家、名校、名课资源,扩大了优质教育资源覆盖面,促进了教育均衡发展。教育是国计、也是民生。各级政府要承担起责任,该投入的必须投入,保障义务教育的公益性,平衡好公办教育和民办教育、政府责任和社会责任,将教育改革发展与解决现实问题结合起来,让教育发展成果更多更公平惠及全体人民。
(四)坚持教育质量的生命线。人民满意的教育必定是高质量的教育。习近平总书记强调,“要深化教育教学改革,强化学校教育主阵地作用,全面提高学校教学质量”。我国人均国内生产总值已超过1.2万美元,教育正加快从“有学上”向“上好学”转变,进入全面提高质量的内涵发展阶段。提高教育质量是一个系统工程,涉及教育观念、教育体制、教学方式的全方位调整,需要做到老师“教好”、学生“学好”、学校“管好”三位一体。义务教育阶段是国民教育的重要基础,是重中之重,近年来重点抓教学改革、课程质量提升,倡导启发式、体验式、互动式教学,培养孩子的良好品行、动手能力、创新精神和人文素养。高等教育是国家发展水平和潜力的重要标志,坚持以“双一流”建设为牵引,强化本科教育,落实教授为本科生上课的规定,同时严格学校管理,让不合格的学生毕不了业,形成鲜明的质量导向。职业教育优化类型定位,突出职业教育特点,促进提质培优,推动教师教材教法改革,实践性教学课时占总课时一半以上。牢固树立教育质量观,把促进人的全面发展、适应国家社会需要作为衡量教育质量的标准,以提高教育质量为导向完善管理制度和工作机制,统筹教育发展的规模、结构、效益,把资源配置和学校工作重心集中到教育教学上来,全面提高各级各类教育的质量。
'''
phrase_list = HanLP.extractPhrase(text, 5)
print(phrase_list)运行结果如下:
[教育质量, 全面发展, 德智体美劳全面, 人才成长, 中国共产党领导]目前该模块只支持提取二元语法短语。在另一些场合,关键词或关键短语依然显得碎片化,不足以表达完整的主题。这时通常提取中心句子作为文章的简短摘要,而关键句的提取依然是基于 PageRank 的拓展。
四、 关键句提取
由于一篇文章中几乎不可能出现相同的两个句子,所以朴素的 PageRank 在句子颗粒度上行不通。为了将 PageRank 利用到句子颗粒度上去,引人 BM25 算法衡量句子的相似度,改进链接的权重计算。这样窗口的中心句与相邻的句子间的链接变得有强有弱,相似的句子将得到更高的投票。而文章的中心句往往与其他解释说明的句子存在较高的相似性,这恰好为算法提供了落脚点。
1.BM25
在信息检索领域中,BM25 是TF-IDF的一种改进变种。TF-IDF衡量的是单个词语在文档中的重要程度,而在搜索引擎中,查询串(query)往往是由多个词语构成的。如何衡量多个词语与文档的关联程度,就是BM25所解决的问题。 形式化的定义 Q 为查询语句,由关键字 q1 到 qn 组成,D 为一个被检索的文档,BM25度量如下:
$$
\operatorname{BM} 25(D, Q)=\sum_{i=1}^{n} \operatorname{IDF}\left(q_{i}\right) \cdot \frac{\operatorname{TF}\left(q_{i}, D\right) \cdot\left(k_{1}+1\right)}{\operatorname{TF}\left(q_{i}, D\right)+k_{1} \cdot\left(1-b+b \cdot \frac{|D|}{\operatorname{avg} D L}\right)}
$$
2.TextRank
有了BM25算法之后,将一个句子视作查询语句,相邻的句子视作待查询的文档,就能得到它们之间的相似度。以此相似度作为 PageRank 中的链接的权重,于是得到一种改进算法,称为TextRank。它的形式化计算方法如下:
$$
\mathrm{WS}\left(V_{i}\right)=(1-d)+d \times \sum_{V_{j} \in \ln \left(V_{i}\right)} \frac{\operatorname{BM} 25\left(V_{i}, V_{j}\right)}{\sum_{V_{k} \in O u t\left(V_{j}\right)} \operatorname{Bu} 2 \mathrm{~s}\left(V_{k}, V_{j}\right)} \mathrm{WS}\left(V_{j}\right)
$$
其中,WS(Vi) 就是文档中第 i 个句子的得分,重复迭代该表达式若干次之后得到最终的分值,排序后输出前 N 个即得到关键句。代码如下:
from pyhanlp import *
"""自动摘要"""
document = '''当前,世界百年未有之大变局加速演进,中华民族伟大复兴进入不可逆转的历史进程。党的二十大报告明确了新时代新征程党和国家所处的历史方位,对以中国式现代化全面推进中华民族伟大复兴作出一系列重大部署。推动经济社会发展、提高综合国力和国际竞争力,归根结底要靠人才。教育是提高人民综合素质、促进人的全面发展的重要途径,是民族振兴、社会进步的重要基石,是对中华民族伟大复兴具有决定性意义的事业。强国必先强教,中国式现代化需要教育现代化的支撑。在新的起点上,教育工作要深入贯彻习近平总书记关于教育的重要论述,全面落实党的教育方针,坚持为党育人、为国育才,遵循教育规律和人才成长规律,顺应社会主要矛盾的变化,以高质量发展为主线,以深化教育改革为动力,以凝聚人心、完善人格、开发人力、培育人才、造福人民为目标,健全学校、家庭、社会育人机制,培养德智体美劳全面发展的社会主义建设者和接班人,加快建设教育强国、办好人民满意的教育。
'''
TextRankSentence = JClass("com.hankcs.hanlp.summary.TextRankSentence")
sentence_list = HanLP.extractSummary(document, 3)
print(sentence_list)结果如下:
[教育是提高人民综合素质、促进人的全面发展的重要途径, 对以中国式现代化全面推进中华民族伟大复兴作出一系列重大部署, 遵循教育规律和人才成长规律]新词提取与短语提取,关键词与关键句的提取,在原理上都是同一种算法在不同文本颗粒度上的应用。值得一提的是, 这些算法都不需要标注语料的参与,然而效果非常有限。对于同一个任务,监督学习方法的效果通常远远领先于无监督学习方法。