EM 算法,全称 Expectation Maximization Algorithm。期望最大算法是一种迭代算法,用于含有隐变量(Hidden Variable)的概率参数模型的最大似然估计或极大后验概率估计。
EM 算法的核心思想非常简单,分为两步:Expection-Step 和 Maximization-Step。E-Step 主要通过观察数据和现有模型来估计参数,然后用这个估计的参数值来计算似然函数的期望值;而 M-Step 是寻找似然函数最大化时对应的参数。由于算法会保证在每次迭代之后似然函数都会增加,所以函数最终会收敛。
一、极大似然估计
1.EM算法是含有隐变量的概率模型极大似然估计或极大后验概率估计的迭代算法。含有隐变量的概率模型的数据表示为$\theta$ )。这里,$Y$是观测变量的数据,$Z$是隐变量的数据,$\theta$ 是模型参数。EM算法通过迭代求解观测数据的对数似然函数${L}(\theta)=\log {P}(\mathrm{Y} | \theta)$的极大化,实现极大似然估计。每次迭代包括两步:
$E$步,求期望,即求$logP\left(Z | Y, \theta\right)$ )关于$ P\left(Z | Y, \theta^{(i)}\right)$)的期望:
$$Q\left(\theta, \theta^{(i)}\right)=\sum_{Z} \log P(Y, Z | \theta) P\left(Z | Y, \theta^{(i)}\right)$$
称为$Q$函数,这里$\theta^{(i)}$是参数的现估计值;
$M$步,求极大,即极大化$Q$函数得到参数的新估计值:
$$\theta^{(i+1)}=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right)$$
在构建具体的EM算法时,重要的是定义$Q$函数。每次迭代中,EM算法通过极大化$Q$函数来增大对数似然函数${L}(\theta)$。
2.EM算法在每次迭代后均提高观测数据的似然函数值,即
$$P\left(Y | \theta^{(i+1)}\right) \geqslant P\left(Y | \theta^{(i)}\right)$$
在一般条件下EM算法是收敛的,但不能保证收敛到全局最优。
3.EM算法应用极其广泛,主要应用于含有隐变量的概率模型的学习。高斯混合模型的参数估计是EM算法的一个重要应用。
在统计学中,似然函数(likelihood function,通常简写为likelihood,似然)是一个非常重要的内容,在非正式场合似然和概率(Probability)几乎是一对同义词,但是在统计学中似然和概率却是两个不同的概念。概率是在特定环境下某件事情发生的可能性,也就是结果没有产生之前依据环境所对应的参数来预测某件事情发生的可能性,比如抛硬币,抛之前我们不知道最后是哪一面朝上,但是根据硬币的性质我们可以推测任何一面朝上的可能性均为50%,这个概率只有在抛硬币之前才是有意义的,抛完硬币后的结果便是确定的;而似然刚好相反,是在确定的结果下去推测产生这个结果的可能环境(参数),还是抛硬币的例子,假设我们随机抛掷一枚硬币1,000次,结果500次人头朝上,500次数字朝上(实际情况一般不会这么理想,这里只是举个例子),我们很容易判断这是一枚标准的硬币,两面朝上的概率均为50%,这个过程就是我们运用出现的结果来判断这个事情本身的性质(参数),也就是似然。
$$P(Y|\theta) = \prod[\pi p^{y_i}(1-p)^{1-y_i}+(1-\pi) q^{y_i}(1-q)^{1-y_i}]$$
二、R示例
1.三硬币模型
假设有A,B,C三枚硬币,其正面出现的概率分别为a,b,c。进行如下掷硬币试验:先掷硬币A,根据其结果选出硬币B或C,正面选B,反面选C;然后掷出选的硬币,根据结果正面记作1,反面记作0;独立重复n次实验,观测结果如下:
$$1,1,0,1,0,0,1,0,1,1$$
假设只能观测掷硬币的结果,不能观测掷硬币过程,试估计三枚硬币正面出现的概率,即三硬币模型参数。
- E step:
$$\mu^{i+1}=\frac{\pi (p^i)^{y_i}(1-(p^i))^{1-y_i}}{\pi (p^i)^{y_i}(1-(p^i))^{1-y_i}+(1-\pi) (q^i)^{y_i}(1-(q^i))^{1-y_i}}$$ - M step:
$$\pi^{i+1}=\frac{1}{n}\sum_{j=1}^n\mu^{i+1}_j$$ $$p^{i+1}=\frac{\sum{j=1}^n\mu^{i+1}_jy_i}{\sum{j=1}^n\mu^{i+1}_j}$$ $$q^{i+1}=\frac{\sum{j=1}^n(1-\mu^{i+1})_jy_i}{\sum{j=1}^n(1-\mu^{i+1}_j)}$$
# e_step
e_step <- function(data,a,b,c){
p1 <- a*b^data*(1-b)^(1-data)
p2 <- (1-a)*c^data*(1-c)^(1-data)
u <- p1/(p1+p2)
return(u)
}
em_fit <- function(data,a,b,c){
N <- length(data)
cat("init prob:",a,b,c,"\n",sep = " ")
theta <- 1
i <- 1
while (theta > 0.0001) {
# e_step
u <- e_step(data,a,b,c)
# m_step
a_tmp <- 1/N*sum(u)
b_tmp <- sum(u*data)/sum(u)
c_tmp <- sum((1-u)*data)/sum(1-u)
cat(i,":",a_tmp,b_tmp,c_tmp,"\n",sep = " ")
i <- i+1
theta <- sum(abs(c(a_tmp,b_tmp,c_tmp)-c(a,b,c)))
a <- a_tmp;b <- b_tmp;c <- c_tmp
}
return(c(a,b,c))
}
data <- c(1,1,0,1,0,0,1,0,1,1)
res <- em_fit(data,0.5,0.5,0.5)2.高斯混合模型的参数估计
高斯混合模型是指具有如下概率分布的模型:
$$P(y \mid \theta)=\sum_{k=1}^{K} \alpha_{k} \phi(y \mid \theta_{k})$$
其中,$\alpha_k$是系数,$\alpha_k \ge0$, $\phi(y \mid \theta_{k})$是高斯分布密度,$\theta_k=(\mu_k,\delta^2_k)$,成为第k个分模型。
$$\phi\left(y \mid \theta_{k}\right)=\frac{1}{\sqrt{2 \pi} \sigma_{k}} \exp \left(-\frac{\left(y-\mu_{k}\right)^{2}}{2 \sigma_{k}^{2}}\right)$$
一般混合模型可由任意概率密度代替上式高斯分布密度。
- E step
依据当前模型参数,计算分模型k对观测数据$y_i$的响应度:
$$\hat{\gamma}_{j k}=\frac{\alpha{k} \phi\left(y_{j} \mid \theta_{k}\right)}{\sum_{k=1}^{K} \alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)}, \quad j=1,2, \cdots, N ; \quad k=1,2, \cdots, K$$ - M step
$$\hat{\mu}_{k}=\frac{\sum{j=1}^{N} \hat{\gamma}_{j k} y{j}}{\sum_{j=1}^{N} \hat{\gamma}_{j k}}$$
$$\delta^2 = \frac{ \sum_{ k = 1 }^{ N } \hat \gamma_{ik} { ( { y }_{ j } – { \mu}{ k } ) }^{ 2 } }{ \sum_{ j = 1 }^{ N } \hat \gamma_{jk}} $$
$${ a }_{ k } = \frac{ \sum{ j = 1 }^{ N } \hat \gamma_{ jk} }{ N }$$
gauss <- function(data,mu,sd){
res <- (1/(sqrt(2*pi)*sd))*exp(-(data-mu)^2/(2*sd^2))
return(res)
}
E_step <- function(data,alpha1,mu1,sd1,alpha2,mu2,sd2){
gamma1 <- alpha1*gauss(data,mu1,sd1)
gamma2 <- alpha2*gauss(data,mu2,sd2)
resp1 <- gamma1/(gamma1+gamma2)
resp2 <- gamma2/(gamma1+gamma2)
return(list(resp1 = resp1,resp2 = resp2))
}
M_step <- function(data,mu1,mu2,resp1,resp2){
mu1_new <- sum(resp1*data) / sum(resp1)
mu2_new <- sum(resp2*data) / sum(resp2)
sd1_new <- sqrt( sum(resp1*(data-mu1)^2) / sum(resp1))
sd2_new <- sqrt( sum(resp2*(data-mu2)^2) / sum(resp2) )
alpha1_new <- sum(resp1) / length(resp1)
alpha2_new <- sum(resp2) / length(resp2)
return(c(mu1_new = mu1_new,mu2_new = mu2_new,
sd1_new = sd1_new,sd2_new = sd2_new,
alpha1_new = alpha1_new,alpha2_new = alpha2_new))
}
EM_train <- function(data,iter){
# init
alpha1 <- 0.5;mu1 <- 0;sd1 <- 1
alpha2 <- 0.5;mu2 <- 1;sd2 <- 1
iter_ <- 0
while (iter_ < iter) {
iter_ <- iter_+1
resp <- E_step(data,alpha1,mu1,sd1,alpha2,mu2,sd2)
res <- M_step(data,mu1,mu2,resp$resp1,resp$resp2)
alpha1 <- res['alpha1_new']; alpha2 <- res['alpha2_new']
mu1 <- res['mu1_new'];mu2 <- res['mu2_new']
sd1 <- res['sd1_new'];sd2 <- res['sd2_new']
}
return(list(alpha1=alpha1,mu1=mu1,sd1=sd1,
alpha2=alpha2,mu2=mu2,sd2=sd2 ))
}
set.seed(1)
N <- 1000
alpha1 <- 0.3;mu1 <- -2;sd1 <- 0.5
alpha2 <- 0.7;mu2 <- 0.5;sd2 <- 1
data1 <- rnorm(N*alpha1,mu1,sd1)
data2 <- rnorm(N*alpha2,mu2,sd2)
data <- c(data1,data2)
data <- sample(data,length(data)) #打乱顺序
re <- EM_train(data,iter = 500)
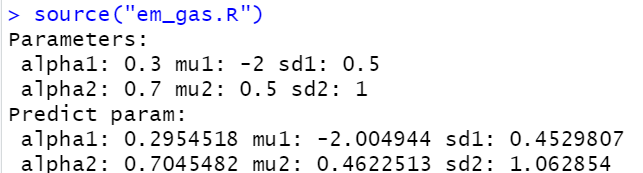
cat("Parameters:","\n",
"alpha1:",alpha1,"mu1:",mu1,"sd1:",sd1,"\n",
"alpha2:",alpha2,"mu2:",mu2,"sd2:",sd2,"\n",sep = " ")
cat("Predict Parameters:","\n",
"alpha1:",re$alpha1,"mu1:",re$mu1,"sd1:",re$sd1,"\n",
"alpha2:",re$alpha2,"mu2:",re$mu2,"sd2:",re$sd2,"\n",sep = " ")